... y me compré un dominio para bloguear más en serio, y mezclando idiomas para ampliar mi target :D.
Ahora me podés encontrar en http://caruizdiaz.com/
lunes, 14 de noviembre de 2011
martes, 5 de abril de 2011
Inactividad
Hace rato que no escribo nada. Durante todo este tiempo fuera estuve trabajando en un montón de proyectos interesantes que voy a estar publicando pronto. Esto es lo que se viene próximamente.
De algún lado estaré sacando tiempo para escribir estas entradas pendientes. :)
- Nuevas funcionalidades para el envío/recepción de SMS usando smsLib
- Text to Speech usando Loquendo
- IVR con voces autoconfigurables usando un abstraction layer sobre Loquendo
- Creación de módulos para Kamailio, 100% hechos en C
De algún lado estaré sacando tiempo para escribir estas entradas pendientes. :)
jueves, 11 de noviembre de 2010
Creando un disector para el Wireshark.
Wireshark es un analizador de paquetes multiplataforma, indispensable para hacer troubleshooting en networking. Cuando surge la necesidad de escribir software que involucre algún tipo de comunicación remota entre 2 o más puntas, muchas veces los problemas de comunicación aparecen. Wireshark es espectacular para depurar este tipo de problemas y hoy por hoy es la herramienta de análisis de tráfico (de red) número uno alrededor del mundo.
Estructuralmente está dividido es una serie de paquetes a los cuales se les llama disectores. Aunque Wireshark es capaz de capturar cualquier tipo de paquetes, el payload o carga útil puede no ser legible si no contamos con un disector especializado que lo corte en porciones entendibles a simple vista.
Estructuralmente está dividido es una serie de paquetes a los cuales se les llama disectores. Aunque Wireshark es capaz de capturar cualquier tipo de paquetes, el payload o carga útil puede no ser legible si no contamos con un disector especializado que lo corte en porciones entendibles a simple vista.
Disector
Básicamente, es un plugin que el programa principal carga para descomponer convenientemente un paquete que responde a las características que el disector determina. Por ejemplo, si llega un paquete en puerto 6789, utilizando como transporte TCP y existe un plugin cargado con éstas dos condiciones satisfechas, el Wireshark utilizará nuestro plugin para descomponer el paquete y mostrarnos su contenido de acuerdo a lo que nosotros hayamos especificado.
El disector es un programa escrito en C que debe ser compilado como shared object (DLL en Windows) y debe contener una serie de funciones estándares a los que Wireshark llamará en tiempo de ejecución para registrar el plugin. La carga del mismo responde al comportamiento típico de dynamic linking, visible en la grandiosa mayoría del software moderno escrito de manera modular.
El disector es un programa escrito en C que debe ser compilado como shared object (DLL en Windows) y debe contener una serie de funciones estándares a los que Wireshark llamará en tiempo de ejecución para registrar el plugin. La carga del mismo responde al comportamiento típico de dynamic linking, visible en la grandiosa mayoría del software moderno escrito de manera modular.
El protocolo CRD
Me tocó hacer un disector de un protocolo complejo pero, por fines pedagógicos, decidí crear uno súper sencillo (al que llamaremos CRD) de modo a demostrar que escribir extensiones no es tan complicado como parece y más bien requiere invertir tiempo en leer la documentación y alguno que otro disector de ejemplo disponible en el trunk de su repositorio SVN.
Abajo especifico la estructura del protocolo. Cuenta con tres campos definidos de la siguiente manera:
Abajo especifico la estructura del protocolo. Cuenta con tres campos definidos de la siguiente manera:
TipoMensaje: determina si el mensaje es de petición o de respuesta.

CódigoRespuesta: determina el resultado de la operación a través de un código numérico.

Mensaje: texto de longitud variable enviado como anexo a la respuesta.

Mensaje: texto de longitud variable enviado como anexo a la respuesta.
Juntando todos los campos quedamos así:

Aplicando la teoría

Ahora que tenemos nuestro protocolo definido podemos empezar la captura pero para esto necesitamos hacer un servidor TCP que nos responda un string válido con las características de nuestro protocolo y con este propósito en mente, escribí un script PHP que responda a eventuales clientes con un texto predeterminado.
$message1 = "01hola mundo a las ";
$socket = stream_socket_server("tcp://localhost:9999", $errno, $errstr, STREAM_SERVER_BIND | STREAM_SERVER_LISTEN);
for(;;)
{
$client = stream_socket_accept($socket);
fwrite($client, $message1.date("Y-m-d h:i:s"));
fclose($client);
}
Con este sencillo script al conectarnos a localhost en puerto 9999 utilizando telnet por ejemplo, obtenemos el siguiente resultado:
carlos@carlosrd-laptop:~> telnet localhost 9999
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
01hola mundo a las 2010-11-13 05:47:13
Ahora, cómo se ve esa captura desde el Wireshark sin nuestro disector?

La verdad que se ve horrible aunque no sea muy difícil leerlo pero cuando trabajemos con un protocolo real, tratar de hacer una lectura comprensiva exitosa desde la vista de arriba, nos tomaría el doble de tiempo y esfuerzo.
Haciendo el disector
Para escribir un disector se necesita tener un conocimiento medio-avanzado del lenguaje C, mientras más complejo sea nuestro protocolo, más difícil será crearle un disector. Además de C, es necesario leer extensivamente la documentación del developer disponible aquí. No pretendo transcribir lo que ya está escrito porque sería una perdida de tiempo así que es muy importante leer el manual antes de seguir. Una vez terminado eso, se necesita tener el ambiente de desarrollo listo para compilar nuestro plugin:

Para escribir un disector se necesita tener un conocimiento medio-avanzado del lenguaje C, mientras más complejo sea nuestro protocolo, más difícil será crearle un disector. Además de C, es necesario leer extensivamente la documentación del developer disponible aquí. No pretendo transcribir lo que ya está escrito porque sería una perdida de tiempo así que es muy importante leer el manual antes de seguir. Una vez terminado eso, se necesita tener el ambiente de desarrollo listo para compilar nuestro plugin:
- Tener instalado los fuentes del Wireshark o haciendo svn checkout de su repositorio
- Tener instalado los archivos de cabecera de libpcap
- Tener instalado automake
La lista de requisitos continúa pero en general no suele ser necesario instalar nada más que lo arriba mencionado.
En mi caso particular de usuario de Linux, tener el ambiente listo me tomó menos de 5 minutos. Si usás Windows esto se puede llegar a complicar (bastante) pero es igualmente posible y documentación sobre cómo hacerlo está disponible en Internet.
El código está comentado en porciones que consideré necesarias. Comenté muy poco lo que ciertas funciones usadas hacen porque eso es más bien ámbito del manual del desarrollador.
Bueno, show me the code:
En mi caso particular de usuario de Linux, tener el ambiente listo me tomó menos de 5 minutos. Si usás Windows esto se puede llegar a complicar (bastante) pero es igualmente posible y documentación sobre cómo hacerlo está disponible en Internet.
El código está comentado en porciones que consideré necesarias. Comenté muy poco lo que ciertas funciones usadas hacen porque eso es más bien ámbito del manual del desarrollador.
Bueno, show me the code:
/**
* CRD Protocol dissector
*
* Carlos Ruiz Díaz
*
* carlos.ruizdiaz@gmail.com
* http://tebicuary.blogspot.com/
* @caruizdiaz
*
* Asunción, Paraguay - November 2010
*
*/
//#define IGNORE
#ifndef IGNORE
#ifdef HAVE_CONFIG_H
# include "config.h"
#endif
#include <stdio.h>
#include <epan/packet.h>
#include <string.h>
/*
* Protocol Logic Implementation
*/
#define _REQUEST_VALUE 0
#define _RESPONSE_VALUE 1
/*
* Definimos el nombre corto del protocolo que aparecerá en la vista
* de disectores instalados
*
*/
#define PROTO_TAG_CRD "CRD"
/*
* Variable que contiene el ID que será asignado dinámicamente a nuestro disector por el Wireshark
*/
static int proto_crd = -1;
static dissector_handle_t data_handle = NULL;
static dissector_handle_t crd_handle = NULL;
static void dissect_crd(tvbuff_t *tvb, packet_info *pinfo, proto_tree *tree);
static void dissect_content(tvbuff_t *tvb, proto_tree *tree);
static void substr(const char* origin, int start, int length, char* result);
/*
* Puerto por defecto en el que el protocolo opera
*/
static int global_crd_port = 9999;
/*
* value_string es una estructura especializada creada para hacer lookups
* usando la función val_to_str() a través de una clave.
*
* Abajo definimos la lista de posibles valores que puede contener el campo
* nro. 2 de nuestro protocolo. Los nros. corresponden al valor transportado
* y la descripción literal a su significado.
*/
static const value_string transaction_result_names[] =
{
{ 00, "Proceso Exitoso" },
{ 01, "Error de proceso" },
{ 02, "Estado desconocido" }
};
static gint hf_crd_pdu = -1;
static gint hf_crd_body_data = -1;
static gint ett_crd_pdu = -1;
static gint ett_crd_body_data = -1;
void proto_reg_handoff_crd(void)
{
static gboolean initialized = FALSE;
if (!initialized)
{
data_handle = find_dissector("data");
crd_handle = create_dissector_handle(dissect_crd, proto_crd);
dissector_add("tcp.port", global_crd_port, crd_handle);
}
}
void proto_register_crd(void)
{
static hf_register_info hf[] =
{
{ &hf_crd_pdu,
{ "PDU", "crd", FT_STRING, BASE_NONE, NULL, 0x0,
"CRD PDU", HFILL }},
{ &hf_crd_body_data,
{ "Body", "crd.body", FT_NONE, BASE_NONE, NULL, 0x0,
"CRD Body contents", HFILL }}
};
static gint *ett[] =
{
&ett_crd_pdu,
&ett_crd_body_data
};
proto_crd = proto_register_protocol("CRD Protocol - Ejemplo de uso", "CRD", "crd");
proto_register_field_array (proto_crd, hf, array_length (hf));
proto_register_subtree_array (ett, array_length (ett));
register_dissector("crd", dissect_crd, proto_crd);
}
static void dissect_crd(tvbuff_t *tvb, packet_info *pinfo, proto_tree *tree)
{
/*
* De acuerdo a la definición de protocolo, el primer byte indica el tipo de mensaje que es.
* 0 para request
* 1 para response
*
* Obtenemos el primer byte y lo convertimos a entero
*/
int type = atoi(tvb_get_string(tvb, 0, 1));
/*
* Chequeamos si en la columna puede escribirse, si se puede,
* escribimos en ella el nombre del protocolo
*/
if (check_col(pinfo->cinfo, COL_PROTOCOL))
col_set_str(pinfo->cinfo, COL_PROTOCOL, PROTO_TAG_CRD);
if (check_col(pinfo->cinfo, COL_INFO))
{
col_clear(pinfo->cinfo, COL_INFO);
/*
* En el cuadro de paquetes capturados, cuando se reciba uno que coincida con nuestro protocolo,
* escribimos como etiqueta el puerto de origen, el de destino y el tipo de mensaje.
*/
col_add_fstr(pinfo->cinfo, COL_INFO, "%d > %d Message Type: [%s]",
pinfo->srcport, pinfo->destport,
((type == _REQUEST_VALUE) ? "REQUEST" : "RESPONSE"));
}
/*
* Si la variable tree es NULL, significa que el usuario no expandió el árbol de captura,
* entonces retornamos porque no hay nada que mostrar
*/
if (tree == NULL)
return;
dissect_content(tvb, tree);
}
static void dissect_content(tvbuff_t *tvb, proto_tree *tree)
{
proto_item *ti = NULL;
/* PDU */
proto_tree *pdu_tree = NULL;
proto_item *pdu_item = NULL;
/* BODY */
proto_tree *body_tree = NULL;
proto_item *body_item = NULL;
/*
* Obtenemos la longitud del mensaje
*/
int message_length = tvb_reported_length(tvb);
/*
* Lo guardamos en un buffer temporal de modo a simplificar el código
*/
char message[message_length + 1];
/*
* Creamos la variable que contendrá el estado (numérico) de la transacción
*/
char transaction_result[3];
/*
* Contenido de longitud variable del texto del mensaje.
*/
int message_text_length = message_length - 2;
char message_text[message_text_length];
/*
* Leemos del buffer de entrada desde el offset 0 hasta el final .
*/
strcpy(message, tvb_get_string(tvb, 0, message_length));
/*
* Extraemos 2 bytes del mensaje original obviando el marcador de tipo de mensaje
*/
substr(message, 1, 2, transaction_result);
/*
* Extraemos el texto del mensaje (de longitud variable) empezando desde el byte nro. 4
* y hasta el final.
*/
substr(message, 2, message_text_length, message_text);
ti = proto_tree_add_item(tree, proto_crd, tvb, 0, -1, FALSE);
pdu_item = proto_tree_add_text(tree, tvb, 0, -1, "PDU");
body_item = proto_tree_add_text(tree, tvb, 0, -1, "Cuerpo");
/* PDU subtree */
pdu_tree = proto_item_add_subtree(pdu_item, ett_crd_pdu);
proto_tree_add_text(pdu_tree, tvb, 0, -1, "Longitud: %d", message_length);
proto_tree_add_text(pdu_tree, tvb, 0, -1, "Contenido: %s", message);
/* BODY subtree */
body_tree = proto_item_add_subtree(body_item, ett_crd_body_data);
proto_tree_add_text(body_tree, tvb, 0, -1, "Resultado: %s",
val_to_str((guint32) atoi(transaction_result),
transaction_result_names,
"Unknown (0x%02x)"));
proto_tree_add_text(body_tree, tvb, 0, -1, "Mensaje: %s", message_text);
}
static void substr(const char* origin, int start, int length, char* result)
{
int currentIndex = 0;
int i = 0;
int end = start + length;
for(i = start; i < end; i++)
result[currentIndex++] = origin[i];
}
#endif // IGNORE
Ahora que ya tenemos el programa listo, lo último que debemos hacer es:
- Llevar el código al directorio plugins de nuestro working copy y crearle un directorio con una estructura copiada de cualquier de otro plugin existente en el mismo directorio
- Crear entradas que referencien a nuestro disector en el archivo configure.in disponible en la raíz de nuestra copia
- Correr el script autogen.sh
- Correr el script configure
- Ir al directorio de nuestro plugin
- Compilar el plugin usando make
- Copiar el resultado de la compilación disponible en .libs/crd.so al directorio de plugins del Wireshark, en mi caso, /usr/lib/wireshark/plugins/1.0.4/
Con estos pasos, la próxima vez que abra el Wireshark, nuestro plugin estará cargado y listo para usarse.
La misma captura que hicimos anteriormente deberá ser visible mucho más elegantemente y quedaría así:
La misma captura que hicimos anteriorment

En vez de tener un paquete capturado mostrando un texto plano, tenemos una separación por bloques, con una descripción de los códigos de los primeros dos campos y la separación del mensaje de respuesta en una etiqueta independiente. Este resultado es mucho más representativo y sin duda, mucho más útil que el anterior.
Eso es todo por ahora, gracias por la lectura :) .
Eso es todo por ahora, gracias por la lectura :) .
martes, 21 de septiembre de 2010
Actualizar anuncios automáticamente en Clasipar.
Todos sabemos que clasipar es el sitio número 1 para la compra/venta de lo que sea en Paraguay.
Cuando uno trata de vender algo le dedica tiempo a buscar compradores o a actualizar sus anuncios de modo a maximizar sus posibilidades y es justamente acá donde entré a improvisar una vez más.
Cuando uno trata de vender algo le dedica tiempo a buscar compradores o a actualizar sus anuncios de modo a maximizar sus posibilidades y es justamente acá donde entré a improvisar una vez más.
Definición de la problemática.
- Tengo varios anuncios ofreciendo productos
- Tengo que entrar a actualizar diariamente mis anuncios pero son varios y me hacen perder mucho tiempo
- Muchas veces me olvido y pierdo oportunidades
El programa
Está hecho en C# (me encanta), corriendo sobre Linux (aunque también funciona en Windows y MacOS) y funcionando sin problemas desde hace más de un mes.
Los espacios de nombre importados hablan de las porciones del framework que usé
Se trata de un Internet bot que recorre clasipar como su fuera un humano. El programa recibe las instrucciones desde un archivo de texto de donde lee qué anuncio(s) actualizar, se conecta a Internet, navega clasipar como si fuera un browser normal (Internet Explorer o Firefox por ejemplo), explora el panel de control del usuario, busca cuál anuncio actualizar y genera un HTTP request con los datos necesarios.
Está hecho en C# (me encanta), corriendo sobre Linux (aunque también funciona en Windows y MacOS) y funcionando sin problemas desde hace más de un mes.
El programa es relativamente corto en líneas de código pero requiere de un background decente sobre el protocolo HTTP. Me tomé mi tiempo snifeando el tráfico de mi browser conectado a clasipar para averiguar qué datos necesitaba y bajo qué formato se hacía la transmisión. Wireshark es un espectáculo para esto y pronto pude hacer reverse engineering de lo que el sitio esperaba. El siguiente paso fue identificar las cookies y las variables POST que cambiaban (y a veces no) en cada petición. Los datos enviados venían de hidden input boxes en algunos casos por lo que no me pude salvar del pattern matching usando expresiones regulares. La basura puesta por google analytics en el request fue especialmente rompebolas y mi falta de experiencia analizando su tráfico me hizo perder tiempo pues no sabía si estos datos eran necesarios y lo peor, de dónde venían. Finalmente, leyendo el fuente HTML de respuesta pude terminar el análisis y reunir lo necesario para construir el programa.
El código
Los espacios de nombre importados hablan de las porciones del framework que usé
using System;El entry point solo contiene lo siguiente ya que la lógica está contenida dentro de la clase ClasiBot.
using System.IO;
using System.Net;
using System.Web;
using System.Text;
using System.Text.RegularExpressions;
using HtmlAgilityPack;
using ClasiparBot.Utils;
El método StartBot()
public static void Main (string[] args)
{
if (args.Length != 1)
{
Debug.PrintError("MainClass.Main(): Invalid command line parameter(s)");
return;
}
if (!File.Exists(args[0]))
{
Debug.PrintError("MainClass.Main(): Configuration file is missing");
return;
}
List <botparameters > botParams = ParseConfigurationFile(args[0]);
foreach(BotParameters botParameter in botParams)
Debug.Notify("MainClass.Main(): Error free? ", new ClasiBot(botParameter).StartBot().ToString().ToUpper());
}
ServicePointManager.Expect100Continue = false;
HttpWebRequest request = (HttpWebRequest) WebRequest.Create(_parameter.ManagementLink);
request.UserAgent = "Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.1.9) Gecko/20100317 SUSE/3.5.9-0.1.1 Firefox/3.5.9\r\n";
request.CookieContainer = new CookieContainer();
HttpWebResponse response = (HttpWebResponse) request.GetResponse();
StreamReader reader = new StreamReader(response.GetResponseStream());
HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(reader.ReadToEnd());
string hashID = ParseHashID(_parameter.ManagementLink.ToString()).Trim();
string authToken = htmlDoc.DocumentNode.SelectSingleNode("//input[@name='authenticity_token']").Attributes["value"].Value;
Debug.Notify("ClasiBot.StartBot(): HashID is", hashID);
Debug.Notify("ClasiBot.StartBot(): Authenticity token is", authToken);
string output = AccessDashboard(request.CookieContainer, hashID, authToken);
output = PerformAnnouncementOperation(request.CookieContainer);
Debug.Notify("ClasiBot.StartBot(): Operation result is '", ParseResult(output), "'");
Este método genera el URI dependiendo de la decisión de actualizar, concretar o eliminar el anuncio.
string BuildURIByOperation(Uri mainUri, AnnouncementOperation operation, Uri announcementUri)
{
string operationUri = "http://" + mainUri.Host + "/ad/";
switch(operation)
{
case AnnouncementOperation.Refresh:
operationUri += "refresh_ad";
break;
case AnnouncementOperation.Delete:
operation
Uri += "delete_ad";
break;
case AnnouncementOperation.MarkAsSold:
operationUri += "mark_as_sol";
break;
}
operationUri += announcementUri.AbsolutePath.Replace(".html", "");
return operationUri;
}
Este método determina el resultado de la operación
public string ParseResult(string html)La salida
{
Match match = Regex.Match(html, @"(?");.+)
if (match.Success)
return match.Groups["message"].Value;
match = Regex.Match(html, @"(?");.+)
if (!match.Success)
throw new Exception("Unable to match result in output html");
return match.Groups["message"].Value;
}

Faltan algunas otras cosas pero esto explica cómo funciona el programa para el que sabe cómo leerlo.
No publico todo el fuente porque aunque lo que hago no es ilegal, puede perjudicar su negocio y lo último que yo quiero es dañar a la industria paraguaya.
Este programa es más bien una h erramienta personal y este post pretende ser un artículo científico para gente que esté interesada en el funcionamiento de los bots.
No publico todo el fuente porque aunque lo que hago no es ilegal, puede perjudicar su negocio y lo último que yo quiero es dañar a la industria paraguaya.
Este programa es más bien una h erramienta personal y este post pretende ser un artículo científico para gente que esté interesada en el funcionamiento de los bots.
miércoles, 25 de agosto de 2010
Un traductor confiable en tu celular
Sigo en la búsqueda del servicio perfecto que a todo el mundo le haga falta y que sea fácil de alcanzar. Como todavía no llego a esa meta sigo tratando y hoy les traigo otro de mis intentos.
¿Cuántas veces necesitaste traducir algo y no pudiste?
En mi caso particular esto es imposible de contabilizar, de hecho, cuando no estoy frente a mi PC conectada a Internet con Google Translator abierto, creo que me resulta difícil sino imposible conseguir una traducción.
Bueno, sin más introducción les presento el traductor español/inglés - inglés/español del mismísimo Google en tu celular!
Bueno, sin más introducción les presento el traductor español/inglés - inglés/español del mismísimo Google en tu celular!
¿Cómo funciona?
- Envía ain + texto-en-castellano al 0981157325 para traducir un texto (o palabra) de castellano a inglés. Ejemplo: ain hola mundo!
- Envía aes + texto-en-inglés al mismo número para el proceso inverso, español a inglés. Ejemplo: aes hello world!
Para hacerte más claro el panorama: ain viene de A-Inglés y aes de A-Español.
Lo único que tenés que hacer ahora es probar :)
Lo único que tenés que hacer ahora es probar :)
viernes, 20 de agosto de 2010
La guía telefónica del país en tu celular
No exagero. Podés tener la guía de todos los usuarios de línea fija (COPACO) en tu celular al alcance de un mensaje de texto.
Muchas veces recibí llamadas de línea baja desde números desconocidos. Muchas de esas llamadas resultaron ser importantes por lo que perdí oportunidades que pude haber aprovechado si hubiera sabido quién llamaba o si hubiera podido identificar el número cuando no estaba registrado entre mis contactos.
Con este nuevo proyecto pretendo ayudar a las personas a identificar esas llamadas perdidas que podrían llegar a ser relevantes en cierto aspecto, así, ya no te quedás con la duda de saber quién te llamó.
Muchas veces recibí llamadas de línea baja desde números desconocidos. Muchas de esas llamadas resultaron ser importantes por lo que perdí oportunidades que pude haber aprovechado si hubiera sabido quién llamaba o si hubiera podido identificar el número cuando no estaba registrado entre mis contactos.
Con este nuevo proyecto pretendo ayudar a las personas a identificar esas llamadas perdidas que podrían llegar a ser relevantes en cierto aspecto, así, ya no te quedás con la duda de saber quién te llamó.
La guía telefónica
Lo que hago no es ilegal en ningún aspecto hasta donde llega mi conocimiento legislativo. Uso una base de datos pública, no muy user friendly, le creé una interfaz un poco más intuitiva y la expongo al público con ánimos de ayudar. Es un servicio gratuito que seguirá vivo mientras dure mi saldo para mensajes. No veo nada de malo en esto.
Cómo usar
Enviá quien + nro-linea-baja al 0981157325 y recibirás un mensaje con el nombre del titular y la dirección registrada.
Por ejemplo: "quien 021998877". Quince segundos después estarás recibiendo la información que buscás.
Por ejemplo: "quien 021998877". Quince segundos después estarás recibiendo la información que buscás.
A tener en cuenta
- Si el número de teléfono que buscas no existe o esta mal formado, no se responde el mensaje informando tal cosa con el fin de ahorrar saldo.
- Si el número que buscas existe, está bien construido y no recibís respuesta, probablemente me quedé sin saldo.
- Si el número que buscás tiene menos de 6 dígitos de largo o más 6 dígitos de largo (longitud(número) <> 6) , tenés que enviar el mensaje de ésta forma: área.número. Por ejemplo: 0541.66777.
Probá
El sistema está on-line, probá, comprobá que funciona y hacele propaganda para que otros puedan usar :) .
viernes, 13 de agosto de 2010
Ejemplo 4: demo usando Windows Forms
Seguimos con los ejemplos. Lo siguiente es un programa hecho en Visual Studio utilizando Windows Forms.
Les cito lo que puede hacer:
Les dejo las capturas.
Les cito lo que puede hacer:
- Enviar mensajes por número
- Enviar mensajes grupales por lista de números cargados a mano o desde un archivo
- Leer los mensajes respondidos por número
- Leer todos los mensajes respondidos
- Chequear mensajes respondidos por tiempo (cada 5 segundos por ejemplo)
Les dejo las capturas.



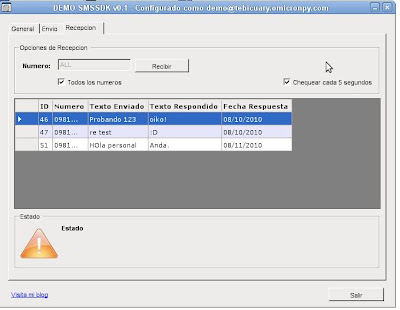
Suscribirse a:
Comentarios (Atom)